BDA420
JSON and Streaming
Contents
JSON
Streaming
→ Batch Processing
→ Stream Processing
→ Socket Processing
JSON
JSON Data
So far, we have only worked with CSV files
Spark has great support for JSON data as well!
JSON data can be saved as either RDDs or Dataframes
The choice of which one to choose depends on the data format, and the intended analysis
JSON Example with RDD
For RDDs, json.loads is used to translate JSON strings into Python objects
import json
path = "/FileStore/tables/sample_users.json"
rdd = spark.sparkContext.textFile(path).map(json.loads)
print(rdd.take(3))
filtered_rdd = rdd.filter(lambda x: \
any(event["type"] == "purchase" for event in x["events"]))
filtered_results = filtered_rdd.collect()
for record in filtered_results:
print(record)
for entry in rdd.collect():
print(f'{entry["name"]} with id: {entry["id"]} '
f'has {len(entry["events"])} events.'
)JSON Example with DF
read.json() translates JSON strings into DFs
For nested arrays, the explod method might be used
from pyspark.sql.functions import col, explode
path = "/FileStore/tables/sample_users.json"
df = spark.read.json(path)
display(df)
df_exploded= df.withColumn("event", explode("events"))
display(df_exploded)
df_exploded2 = df.withColumn("event", explode("events")) \
.select(
col("id"),
col("name"),
col("event.type").alias("type"),
col("event.timestamp").alias("timestamp")
)
display(df_exploded2)Streaming Overview
What is Streaming
Real-time data processing
Stream processing requires working with data that is constantly being updated
Data can come from multiple sources: sensors, IoTs, web applications, APIs, etc.
What is Streaming
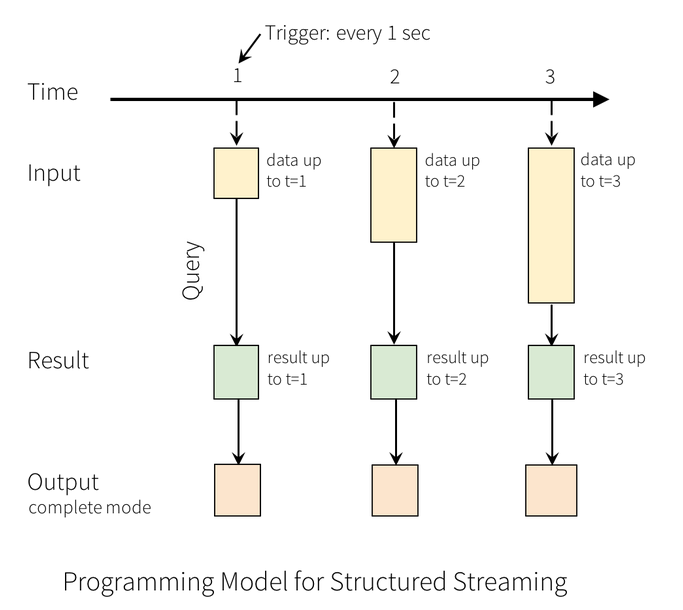
Streaming in Spark
Apache Spark provides a structured streaming architecture
The data stream is treated as an unbounded table that is continuously appended
New data in the stream results in new rows in the unbounded table
Streaming in Spark
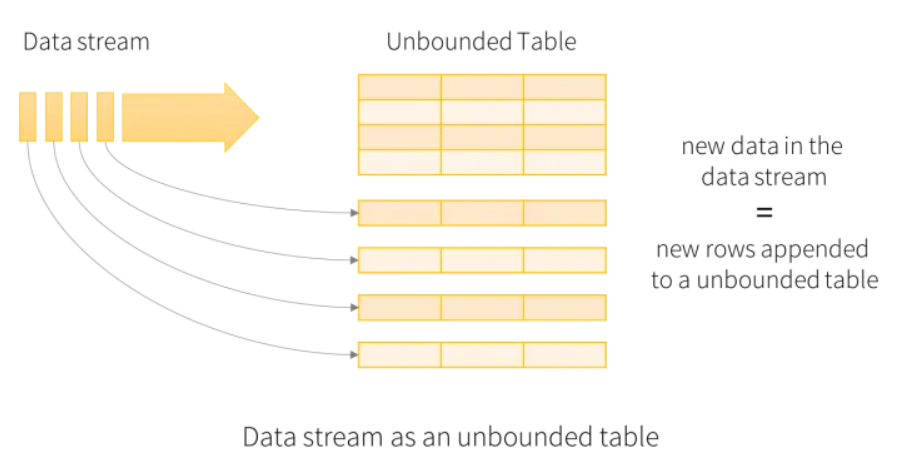
Streaming Components
There are three major components for streaming:
Data Source - Where the data comes from:
Files, Sockets, or an API
Streaming Engine- What we do with the data:
Filtering, Grouping, Sorting
Data Sink - Where we save our results:
Memory, Console, File, etc.
Batch Processing
Batch Processing
Allow us to go over all files in a given directory
Helpful for going over data spread over multiple files
Data Source
from pyspark.sql.types import *
inputPath = "/databricks-datasets/structured-streaming/events/"
jsonSchema = StructType([StructField("time", TimestampType(),True),\
StructField("action", StringType(), True)])
staticInputDF = spark.read.schema(jsonSchema).json(inputPath)
display(staticInputDF)Streaming engine
from pyspark.sql.functions import window, col
staticCountsDF = staticInputDF.groupBy(col("action"), \
window(col("time"), "30 minutes")).count()
display(staticCountsDF)window
The window() function groups together rows that fall within a specified interval
Not to be confused with the Window() class
It generates a single column with two stringType components: one for the start and one for the end time
Data Manipulation
from pyspark.sql.functions import date_format
display(staticCountsDF.groupBy(staticCountsDF["action"]).sum())
display(staticCountsDF.withColumn("time", \
date_format(staticCountsDF["window"].end, "MMM-dd HH:mm"))\
.drop(staticCountsDF["window"])\
.orderBy("time","action"))date_format() outputs a formatted timestamp
Data Sink
For Stream and Socket Processing, a data sink is needed
Data sinks need to be queried using the SQL language*
staticCountsDF.createOrReplaceTempView("static_counts")%sql
select action, sum(count) as total_count from
static_counts group by action
select action, date_format(window.end, "MMM-dd HH:mm") as time,
count from static_counts order by time, actionStream Processing
Stream Processing
Allow us to continuously go over all files in a given directory
The directory can be updated in real time
Helpful for automating tasks
Data Source
from pyspark.sql.types import *
inputPath = "/databricks-datasets/structured-streaming/events/"
jsonSchema = StructType([StructField("time",TimestampType(),True),\
StructField("action", StringType(), True)])
streamingInputDF = spark.readStream \
.schema(jsonSchema) \
.option("maxFilesPerTrigger", 1) \
.json(inputPath)Streaming engine
streamingCountsDF = streamingInputDF.groupBy(col("action"), \
window(col("time"), "1 hour")).count()Data Sink
streamingCountsDF.writeStream \
.format("memory")\
.queryName("counts")\
.outputMode("complete")\
.trigger(processingTime = "5 seconds")\
.start()queryName() sets up the name of the SQL table
outputMode() options are append, complete, and update (link)
Queries
%sql
select action, sum(count) from counts group by action
select action, date_format(window.end, "MMM-dd HH:mm") as time, count
from counts order by time, actionSocket Processing
Socket Streaming
Allow us to treat data coming from a socket
Frequently associated with IoT, sensors, or APIs
In our example, we will collect messages from a Netcat server
Data Source
lines = spark \
.readStream \
.format("socket") \
.option("host", "159.203.31.149") \
.option("port", 9999) \
.load()
Streaming engine
from pyspark.sql.functions import explode, split
words = lines.select(explode(
split(lines.value, " ")).alias("word"))
wordCounts = words.groupBy("word").count()Split and Explode
In the previous example, split is used to break down each message into a list with individual words
explode is used to break down each list into multiple rows
Split and Explode
data = [("Alice", "apple,banana,grape"), ("Bob", "orange,mango")]
df = spark.createDataFrame(data, ["name", "fruits"])
df = df.withColumn("fruits", split(df["fruits"], ","))
display(df)
df_explode = df.select("name", explode(df["fruits"]).alias("fruit"))
display(df_explode)Data Sink
query = wordCounts \
.writeStream \
.outputMode("complete") \
.format("memory")\
.queryName("wordCounts")\
.trigger(processingTime = "1 seconds")\
.start()%sql
select * from wordCounts